Thunder Compute versus GPU Per Hour

Thunder Compute
Ideal Para
Los científicos de datos pueden ejecutar modelos en su GPU deseada sin complicaciones de infraestructura
Los ingenieros de IA pueden prototipar en modo CPU antes de cambiar a GPU para la ejecución
Los desarrolladores pueden realizar simulaciones complejas rápidamente
Las startups pueden aprovechar el poder de la GPU sin costos iniciales significativos
Fortalezas Clave
Acceso a GPU eficiente y rápido
Sin costos de infraestructura iniciales
Recursos escalables para necesidades variables
Características Principales
GPUs virtualizados para mayor eficiencia
Paga solo por el uso activo de GPU
Escala los recursos de GPU sin esfuerzo
Accede a GPUs bajo demanda sin reservas
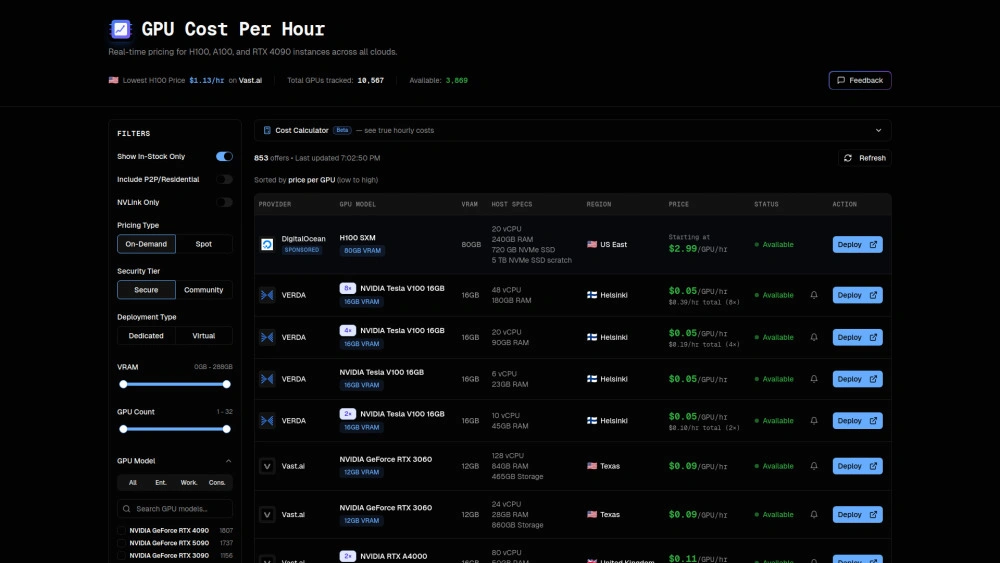
GPU Per Hour
Ideal Para
Encontrar la tarifa horaria más baja para GPUs de alta gama
Comparar AWS vs proveedores especializados como RunPod
Localizar stock de RTX 4090 para cargas de trabajo de ML
Planificar experimentos de ML rentables con presupuesto por hora
Fortalezas Clave
Seguimiento de precios en tiempo real entre 25+ proveedores
Ahorro de costos por comparaciones cara a cara
Filtrar por modelo de GPU, VRAM, región
Características Principales
Precio en tiempo real: Rastrea más de 10,000 GPUs entre 25+ proveedores
Comparaciones cara a cara: Compara proveedores fácilmente
Filtros avanzados: Reduce resultados por modelo de GPU, VRAM, NVLink, región
Calculadora de costos: Estima gastos horarios reales
Cobertura empresarial y de consumo: H100/A100 y RTX 4090/3090