Thunder Compute contre GPU Per Hour

Thunder Compute
Idéal Pour
Les data scientists peuvent exécuter des modèles sur leur GPU souhaité sans tracas d'infrastructure
les ingénieurs IA peuvent prototyper en mode CPU avant de passer au GPU pour l'exécution
les développeurs peuvent exécuter des simulations complexes rapidement
les startups peuvent tirer parti de la puissance du GPU sans coûts initiaux significatifs
Forces Clés
Accès GPU efficace et rapide
Pas de coûts d'infrastructure initiaux
Ressources évolutives pour des besoins variés
Fonctionnalités principales
GPU virtualisés pour une efficacité accrue
Paiement uniquement pour l'utilisation active des GPU
Échelle des ressources GPU sans effort
Accès aux GPU à la demande sans réservations
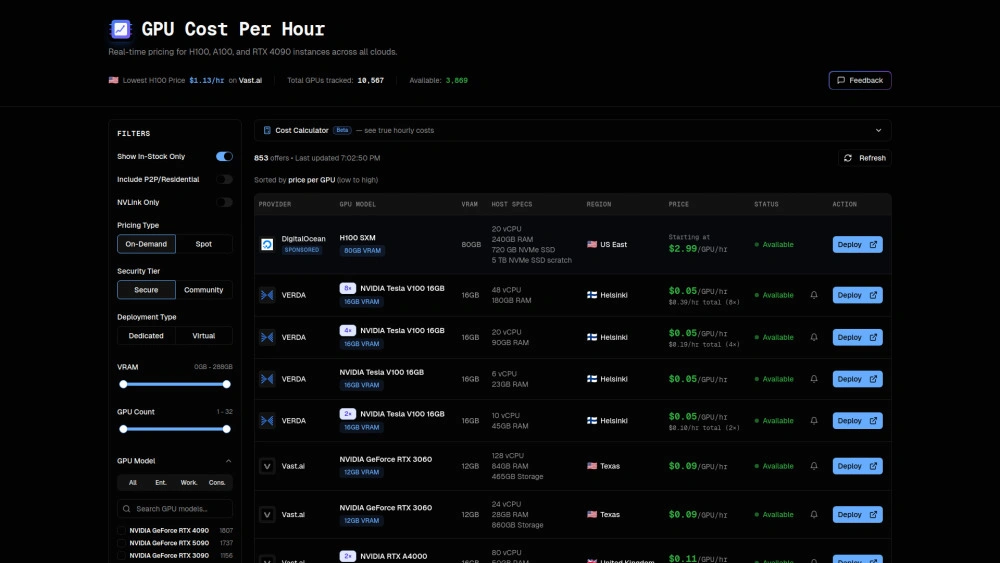
GPU Per Hour
Idéal Pour
Trouver le taux horaire le plus bas pour les GPU haut de gamme
Comparer AWS vs des fournisseurs spécialisés comme RunPod
Localiser le stock RTX 4090 pour les charges ML
Planifier des expériences ML rentables avec un budget horaire
Forces Clés
Suivi des prix en temps réel sur 25+ fournisseurs
Économies réalisées grâce à des comparaisons directes
Filtrer par modèle de GPU, VRAM, région
Fonctionnalités principales
Prix en temps réel : Suivez plus de 10 000 GPU auprès de plus de 25 fournisseurs
Comparaisons directes : comparez facilement les fournisseurs
Filtres avancés : affiner les résultats par modèle GPU, VRAM, NVLink, région
Calculateur de coût : estimer les dépenses horaires réelles
Couverture entreprise et consommateur : H100/A100 et RTX 4090/3090