Thunder Compute versus GPU Per Hour

Thunder Compute
Ideal For
Data scientists can run models on their desired GPU without infrastructure hassle
AI engineers can prototype in CPU mode before switching to GPU for execution
Developers can execute complex simulations quickly
Startups can leverage GPU power without significant upfront costs
Key Strengths
Efficient and fast GPU access
No upfront infrastructure costs
Scalable resources for varying needs
Core Features
Virtualized GPUs for enhanced efficiency
Pay only for active GPU usage
Scale GPU resources effortlessly
Access GPUs on demand without reservations
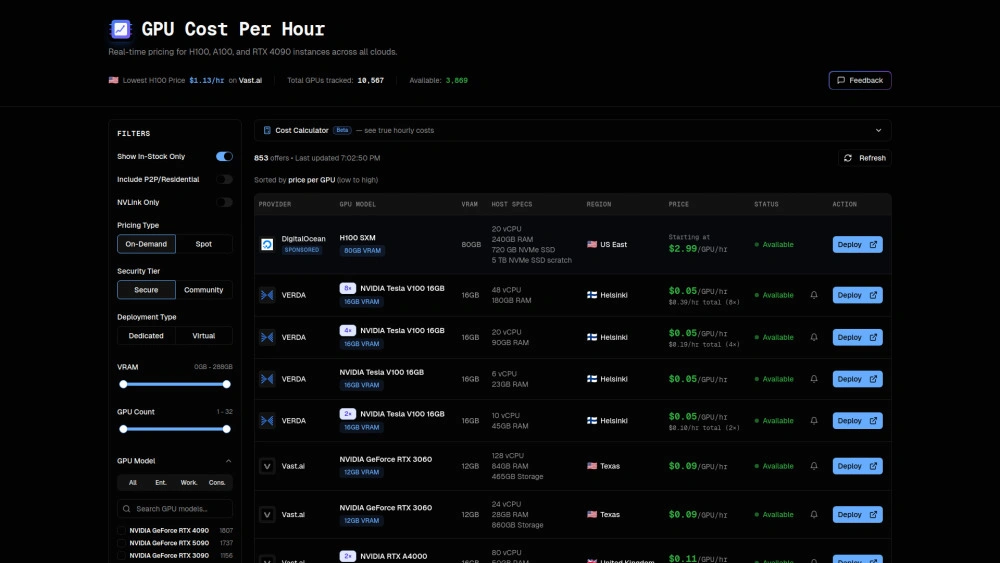
GPU Per Hour
Ideal For
Finding the lowest hourly rate for high-end GPUs
Comparing AWS vs specialized providers like RunPod
Locating RTX 4090 stock for ML workloads
Planning cost-efficient ML experiments with per-hour budgeting
Key Strengths
Real-time price tracking across 25+ providers
Cost savings from head-to-head comparisons
Filter by GPU model, VRAM, region
Core Features
Real-time pricing: Track 10,000+ GPUs across 25+ providers
Head-to-head comparisons: Easily compare providers
Advanced filters: Narrow results by GPU model, VRAM, NVLink, region
Cost calculator: Estimate true hourly expenses
Enterprise & consumer coverage: H100/A100 and RTX 4090/3090