Thunder Compute versus GPU Per Hour

Thunder Compute
Ideal Para
Cientistas de dados podem rodar modelos em sua GPU desejada sem complicações de infraestrutura
Engenheiros de IA podem prototipar em modo CPU antes de mudar para GPU para execução
Desenvolvedores podem executar simulações complexas rapidamente
Startups podem aproveitar o poder da GPU sem custos iniciais significativos
Forças Chave
Acesso GPU eficiente e rápido
Sem custos de infraestrutura inicial
Recursos escaláveis para necessidades variadas
Recursos Principais
GPUs virtualizados para eficiência aprimorada
Pague apenas pelo uso ativo de GPU
Escale recursos de GPU sem esforço
Acesse GPUs sob demanda sem reservas
GPU Per Hour
Ideal Para
Encontrar a menor taxa horária para GPUs de alto desempenho
Comparando AWS vs provedores especializados como RunPod
Localizar estoque de RTX 4090 para cargas de ML
Planejar experimentos de ML eficientes em custo com orçamento por hora
Forças Chave
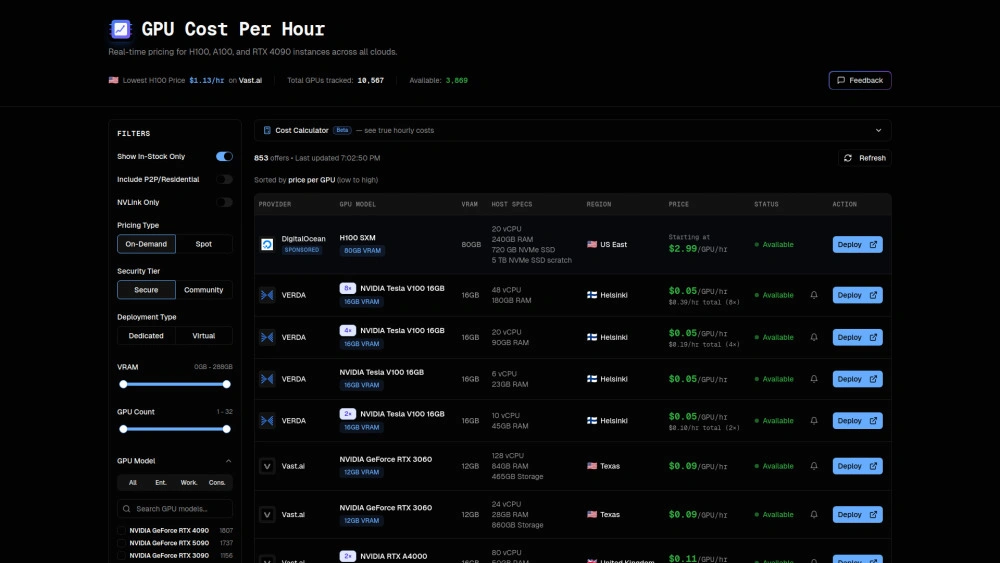
Rastreamento de preço em tempo real entre 25+ provedores
Economia de custo com comparações diretas
Filtrar por modelo de GPU VRAM região
Recursos Principais
Pricing em tempo real: Acompanhe mais de 10.000 GPUs em mais de 25 provedores
Comparações diretas entre provedores: Compare facilmente os provedores
Filtros avançados: Refine os resultados por modelo de GPU, VRAM, NVLink, região
Calculadora de custo: Estime despesas horárias reais
Cobertura empresarial e de consumidor: H100/A100 e RTX 4090/3090