Thunder Compute gegen GPU Per Hour

Thunder Compute
Ideal Für
Datenwissenschaftler können Modelle auf ihrer gewünschten GPU ohne Infrastrukturprobleme ausführen
KI-Ingenieure können im CPU-Modus prototypisieren, bevor sie für die Ausführung zur GPU wechseln
Entwickler können komplexe Simulationen schnell ausführen
Startups können die GPU-Leistung nutzen, ohne erhebliche Vorauszahlungskosten.
Wichtige Stärken
Effizienter und schneller GPU-Zugang
Keine anfänglichen Infrastrukturkosten
Skalierbare Ressourcen für unterschiedliche Bedürfnisse
Kernfunktionen
Virtualisierte GPUs für verbesserte Effizienz
Zahlen Sie nur für aktive GPU-Nutzung
GPU-Ressourcen mühelos skalieren
Greifen Sie bei Bedarf ohne Reservierungen auf GPUs zu
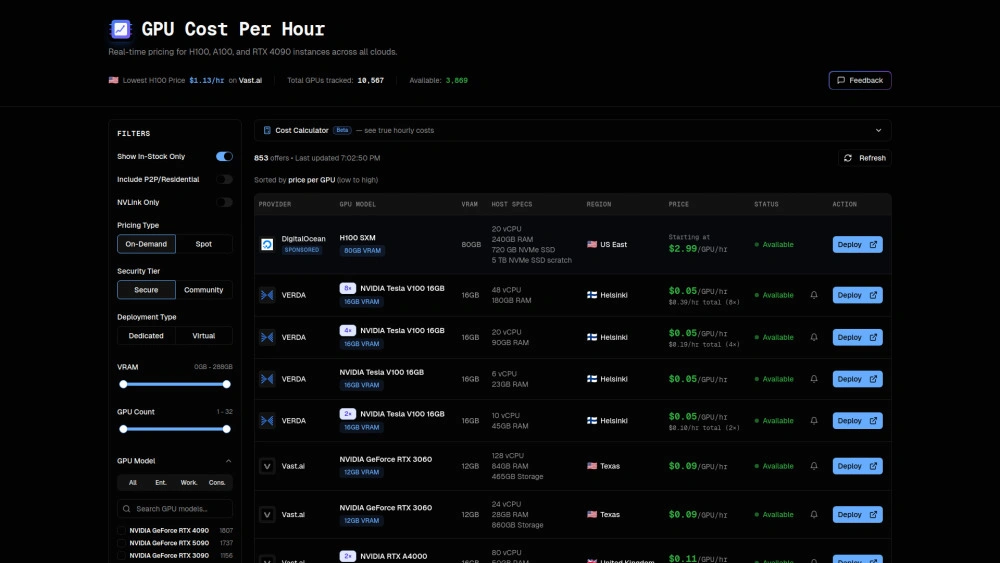
GPU Per Hour
Ideal Für
Finden des niedrigsten Stundensatzes für hochwertige GPUs
Vergleich von AWS vs spezialisierten Anbietern wie RunPod
Lokalisierung von RTX 4090 Lagerbestand für ML-Arbeitslasten
Planung kosteneffizienter ML-Experimente mit stundenbasierter Budgetierung
Wichtige Stärken
Echtzeit-Preisverfolgung über 25+ Anbieter
Kosteneinsparungen durch Head-to-Head-Vergleiche
Filtern nach GPU-Modell, VRAM, Region
Kernfunktionen
Echtzeitpreise: Verfolgen Sie 10.000+ GPUs über 25+ Anbieter
Gegenüberstellungen Kopf an Kopf: Vergleichen Sie Anbieter einfach
Erweiterte Filter: Beschränken Sie Ergebnisse nach GPU-Modell, VRAM, NVLink, Region
Kostenrechner: Schätzen Sie echte stündliche Ausgaben
Unternehmen & Privatkundenabdeckung: H100/A100 und RTX 4090/3090